写文章的时候,找图是一个比较麻烦的事情,既要找到好看高清的图片,又要规避版权的风险,而国外就有很多免版权的图库,比如pexels、unsplash等等,其中我比较常用的是unsplash。而我就在想,可不可以把unsplash封装成一个api,这样在嵌入一些项目中会比较方便。那么话不多说,一起来看看吧。
其实unsplash官方就已经提供了api接口了,有两种,source api和development api。source api比较简单,无需注册,可以通过关键词搜索获取随机一张相关的图片,并且可以控制返回图片的尺寸(url中的500x0),然后重定向到图片的地址。
https://source.unsplash.com/500x0/?perfume
这个unsplash官方提供的初级api接口每次只能返回一张,而且只能返回某一种大小的图片,当需要很多图片以及不同尺寸的时候就需要申请专业的api(也是免费的),不过需要注册,本着不想麻烦的心,我就打算直接将网页的结果封装成api。
观察了一下搜索结果的页面,发现js中有一些图片的地址了,并且有5种大小格式,组合成json的形式。本来可以通过python 中的json.load()方法直接加载,但是由于这个页面内容太错综复杂,所以我采取一个简单的办法,直接分隔字符串来获取对应的链接。下面就看一下具体的封装代码吧。
import requests
def getImage(keyword):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0'}
response=requests.get('https://unsplash.com/s/photos/'+str(keyword),headers=headers)
raw_json=response.text.split('\\"links\\"',1)[1].rsplit('\\"links\\"',1)[0]
raw_json=raw_json.replace('\\"','"')
raw_imgs=[r.split('",',1)[0] for r in raw_json.split('"raw":"')[1:]]
full_imgs=[r.split('",',1)[0] for r in raw_json.split('"full":"')[1:]]
regular_imgs=[r.split('",',1)[0] for r in raw_json.split('"regular":"')[1:]]
small_imgs=[r.split('",',1)[0] for r in raw_json.split('"small":"')[1:]]
thumb_imgs=[r.split('"},',1)[0] for r in raw_json.split('"thumb":"')[1:]]
photos=[]
for i in range(len(raw_imgs)):
photo={}
photo['raw']=raw_imgs[i]
photo['full']=full_imgs[i]
photo['regular']=regular_imgs[i]
photo['small']=small_imgs[i]
photo['thumb']=thumb_imgs[i]
photos.append(photo)
return photos
每一个图片分别有5种格式的大小,raw、full、regular、small、thumb,最后返回由每一个图片dict组成的列表。看代码比较直观。
之后通过getImage()就可以获得对应的图片列表,而且每一张图片都有5种不同的大小格式。
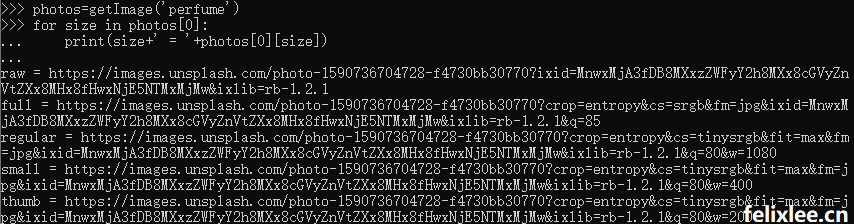
另外如果需要镜像加速的话,可以将函数中的'https://unsplash.com/s/photos/'替换成对应的镜像站搜索地址,比如dogedoge的就是'https://unsplash.dogedoge.com/s/photos/',这样也可以达到提高响应速度呢。有了封装好的api,之后在嵌入一些项目中就会比较方便。
当然以上这些也可以直接通过unsplash提供的官方api获取,更加方便。
添加多语言支持
unsplash不像pexels,它并没有多语言支持,只能用英文搜索,所以我们可以在这个api之上,再多添加一个翻译的功能,这里我用的是谷歌翻译的接口,我封装成了一个简单的函数。
import requests
def translate(q,tl,sl='auto'): #sl是源语言 tl是目标语言 q是需要翻译的内容
base_url='https://translate.google.cn/translate_a/single?client=gtx&dt=t&dt=bd&dt=rm&dj=1&ie=UTF-8&oe=UTF-8&sl=%s&tl=%s&hl=zh-CN&tk=&q=%s'
tran_url=base_url % (sl,tl,q)
response=requests.get(tran_url)
rjson=response.json()
sentences=rjson['sentences']
rewords=''
for s in sentences:
if 'trans' in s:
rewords=rewords+s['trans']
return rewords
然后我们把这个翻译的功能集成到搜索图片的函数中
def getImage(keyword):
...
keyword=translate(keyword,'en-US')
...
这样我们就可以通过中文或者其他语言来搜索图片了。

以上便是将unsplash网页内容封装成api的简单介绍啦,还添加了一个多语言支持的功能。之后在一些项目中都可以嵌入使用。当然,以上除了翻译的功能外,其他的功能unsplash官方提供的开发api都支持,而且还可以获取更多的详细信息,包括时间、上传者等等,有需要的小伙伴也可以去看看。
-
最新文章
- 爱尔法鲁酒吧问题python实现,复杂经济学博弈论自组织自适应系统
- python字体子集化
- 一些用平板画的画和用flipaclip画的动画
- phpcms通用缓存装饰器,给函数的输出增加缓存
- python根据行业根词及百度百科提取行业属性
- python使用朴素贝叶斯实现简单中文文本分类
- 基于时间戳与对称加密实现简单的token验证
- 递归打印出树形结构数据(多层级数据)(小思考)
-
最新随笔
- 海洋公园逛逛(ps:北极熊馆动物状态都感觉不太好)
- 半夜梦到一段诗,但醒来不太记得全部,让deepseek续写一下,我只记得前面是: “当元论状赵金海,不出凭栏***” 至于为什么会突然起来记下这段诗,是空调水一直滴在琴上,给我吵醒了(惊醒!),深圳台风刚过,湿度大
- 渐变
- 周末打开摩尔庄园给拉姆喂点吃的,碰到个大佬带着同服的一群人去一大堆以前的老场景逛嘞。对我来说,印象最深刻的是浆果丛林刚开放的那段时间。
- 稍微调整一下首页样式(旧 → 新)
- 给随笔页面加了个动态加载的功能,不然一次性加载太多图片访问有点慢
- 这个桥去年来看的时候貌似还没有
- 中秋经典BGM:滴滴滴
 粤公网安备 44030702002444号
粤公网安备 44030702002444号