之前在看《数据科学入门》——Joel Grus的第13章朴素贝叶斯算法的时候,文章内根据朴素贝叶斯算法实现了一个简单的英文垃圾邮件筛选器,跟着做了一下,还是很好理解的,后面拓展了一下思维,发现运用到中文文本分类上还是很容易实现的,不过是将垃圾邮件区分的二分类问题转换成多分类问题,几分类问题取决于你提前设置的需要区分的类别,那么下面就写一下我的实现过程,抛砖引玉,和大家一起进步。
朴素贝叶斯算法理论
这个部分网上已经有很多通俗易懂地文章和视频将这个算法讲得很透彻了,不需要什么统计学基础也可以很容易理解,我就不再赘述了,这里推荐一些我看过的一些,比较好理解的。
【[5分钟学算法] #02 朴素贝叶斯 写作业还得看小明-哔哩哔哩】 https://b23.tv/tjH0mpe
任务目标
本文的目标是实现简单的中文文本分类,那么首先需要确定是几分类问题,这里我直接以国内知名门户网站搜狐的分类来作为我们的需要的分类结果,后续我们还需要通过搜狐的文章作为训练数据与测试数据。
不多不少正好十个,那么这个机器学习项目就是一个十分类问题
types=["新闻","体育","汽车","房产","旅游","教育","时尚","科技","财经","娱乐"]
准备数据
通过python的requests包采集搜狐新闻,对采集的文章做简单的清洗,将html标签全部清除,将多余的空格和换行符去除,并预先做好对应的标记,储存在excel文件中。
dataset.xlsx

其中第一列为文本内容,第二列为types中对应类别的下标索引,比如6就对应types中的第七个元素【时尚】,就表示这篇文章属于【时尚】分类,这个是我们预先标记好的。
我采集了100条内容,每个分类采集了10条。在投入实际生产任务时,一般来说应该准备更多不同的数据,这样泛化能力与准确度都会有一定的提升。
加载数据方法
因为我们的训练数据是储存在xlsx文件中的,所以还需要写一个加载xlsx的方法,这里我们用python中的openpyxl来帮助我们完成这个任务
import openpyxl
def loadExcel(file_path,sheet_name):
wb = openpyxl.load_workbook(filename=file_path,read_only=True)
sheet=wb.get_sheet_by_name(sheet_name)
datas=[]
for row in sheet.iter_rows():
data=[col.value for col in row]
datas.append(data)
return datas
加载数据集后,打乱顺序,提取70条作为训练集,30条作为测试集。
文本分词
中文文本不像英文那样,天然可以通过空格来分词,中文不是靠空格来分词的,所以第一步我们就需要思考如何将中文分词,这里我用到的是jieba分词,这个是中文分词领域做得比较好的工具了,通过jieba分词将文本分词,然后通过停词表将文本中类似“的”、“是”以及标点符号之类没有实际意义的词去除,避免影响分类效果。(本文的主要任务是文本分类,而分词又是nlp中的一大研究方向,我就暂时不在这里过多投入,所以就使用jieba分词来帮助我们完成该任务)
import jieda
import jieba.analyse
def getStops(fpath="stops.txt"):#加载停词表
f=open(fpath,'r',encoding="utf-8")
page=f.read()
f.close()
stops=page.split("\n")
return stops
def tokenize(content):#通过jieba分词,然后用停词表剔除停词,最后去重返回
keywords=jieba.cut(content)
stops=getStops()
newkeywords=[]
for kw in keywords:
if kw not in stops:
newkeywords.append(kw)
return set(newkeywords)
我们需要准备一个停词表,一行一个停词,类似下方
stops.txt
--
?
“
”
的
吧
则
完成后我们可以做一个简单的测试

计算一系列单词在各个类别出现的频次
这部分用代码注释解释
from collections import defaultdict
#返回一系列单词分别出现在各个类别的次数 有几个类别,value就有几个元素,比如是10个分类就是一个10个元素的list,初始值都是0,用于储存该关键词在不同类别出现的次数。
def count_words(training_set,types):
counts=defaultdict(lambda:[0 for i in range(len(types))])
for content,type_index in training_set:
for keyword in tokenize(content):
counts[keyword][type_index] += 1 #counts[keyword][0]是单词出现在类别0中的数量 counts[keyword][1] 则是该单词在类别1中出现的次数,以此类推
return counts
defaultdict是python的一个工厂函数,可以在传入某个不存在的key的时候,返回一个默认的值,故名为defaultdict,它接受一个函数作为返回的默认值。
import random
dataset=loadExcel("dataset.xlsx","Sheet1")#加载数据集
random.shuffle(dataset)#打乱数据集
#拆分训练集与测试集
training_set=dataset[:70]#取打乱后的数据集的前70条作为训练集
test_set=dataset[70:]#取后30条作为测试集
word_counts=count_words(training_set,types)#计算词频
可以打印word_counts看下效果(及时打印出数据查看有助于理解),我随便截一部分查看

观察上面的数据,可以看到【半场】、【球员】这类词在【体育】分类中出现较多,比如【球员】一词就在训练集中的5篇体育分类文章中出现过,而在其他分类的文章中则没有出现过,这么看来包含这些词的文章更有可能是这些分类。
计算一系列单词在各个类别出现的频率
def word_probabilities(counts,type_total_counts,types,k=0.5):
word_probs=[]
for w,w_all_counts in counts.items():
word_prob=[w]
word_prob_list=[]
for i in range(len(w_all_counts)):
w_onetype_counts=w_all_counts[i]
onetype_total_counts=type_total_counts[i]
word_prob_list.append((w_onetype_counts+k)/(onetype_total_counts+len(types)*k))
word_prob.append(word_prob_list)
word_probs.append(word_prob)
return word_probs
传入的counts是通过word_counts得到的结果,type_total_counts 为各个类别的总数list,打比方如果训练数据集每个分类都只有一个,那么就传入[1,1,1,1,1,1,1,1,1,1],而k则是一个伪计数,防止某些类别数量为0时使分母为零,进而使得结果无意义,有了k的加入,这样即使某些类别数量为0,概率也是一个非零值。
下面测试一下,首先获取训练数据集中各个类别的总数type_total_counts,再计算概率


word_probabilities函数返回的结果格式为
[
["单词1",["单词1在分类1的概率","单词1在分类2的概率","单词1在分类3的概率",...,"单词1在分类10的概率"]],
["单词2",["单词2在分类1的概率","单词2在分类2的概率","单词2在分类3的概率",...,"单词2在分类10的概率"]],
...
["单词n",["单词n在分类1的概率","单词n在分类2的概率","单词n在分类3的概率",...,"单词n在分类10的概率"]]
]
打印word_probs看一下,我截取一部分

比如上图中【购置】一词,概率最大的是0.1100,而其对应的分类为房产,所以文章包含某些词确实可以作为区分类别的关键。
根据训练的概率对新内容进行预测
对未知的数据给出结果才是分类机器学习的主要目的,所以我们需要通过上面训练得到的单词概率与需要分类的类别,对新数据做出预测。
import math
#根据训练的概率,返回新文本属于各类别的概率
def word_probability(word_probs,content,types):
content_words=tokenize(content)
log_probs_type=[0.0 for i in range(len(types))]
for word,probs in word_probs:
if word in content:#如果文本包含训练数据中的某个词就在(文本属于某个类别的概率)上加上(这个词在某个类别的概率)
for i in range(len(probs)):
prob=probs[i]
log_probs_type[i] += math.log(prob)
else:#如果文本不包含训练数据中的某个词就在(文本属于某个类别的概率)上加上(1 减去 这个词在某个类别的概率)
for i in range(len(probs)):
prob=probs[i]
log_probs_type[i] += math.log(1-prob)
return log_probs_type
计算机对于非常接近0的浮点数计算并不是很擅长,很多小数连乘可能会出现浮点数下溢的情况,即超出计算机所能表示的小数,这里就用等效的代数计算处理浮点数计算。朴素贝叶斯本质就是多种概率的相乘,而那么多浮点数概率连乘,几乎不可避免地会出现下溢,所以这里使用对数来代替运算,根据对数的运算性质,log(ab)=log(a)+log(b),log(a/b)=log(a)-log(b),引入math包帮助我们处理这个问题。
而计算得出的对数,如果直接进行exp(),还是会下溢,这里我就直接返回对数,对对数进行比较。因为log函数在底a>1的情况下属于递增函数,math.log默认使用e作为底,e大于1,属于增函数,是正相关的,所以我们直接根据对数进行比较也能得出同样的结果。(完整的朴素贝叶斯中,单词概率相乘后得到属于每个分类的概率,还需要将所有分类的概率相加,再返回各个分类概率除以(所有分类的概率总和),而此步骤其实对于比较结果其实并不影响,故直接省去这步)
然后我们随便输入一段文本进行测试

暂时看来还是可以预测正确的,那么下面我们用上面分出的30条测试集数据测试一下这个模型的准确性。
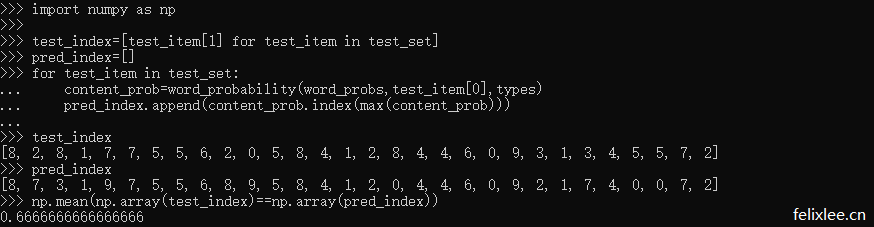
可以看出,预测的准确度在66.66%,准确率并不是太高,不过这主要与训练数据过少有很大关系,本文仅使用了70条文本作为训练数据,而观察上面的单词概率可以发现,一些比较通用、没有特别的行业属性的词,如【成效】仅仅出现了一次,而且还出现在体育分类中,这样对于测试数据的预测是有影响的,而当训练数据增多,如增至上千、上万,甚至更多,准确率是会有不错的提升的。
封装打包
可以将上属代码打包到一个类中,方便组织使用
class NaiveBayesClassifier:
def __init__(self,types,k=0.5):#初始化
self.k=k
self.word_probs=[]
self.types=types
def train(self,training_set):#训练方法
type_total_counts=[0 for i in range(len(self.types))]
for content,index in training_set:
type_total_counts[index] += 1
word_counts=count_words(training_set,self.types)
self.word_probs=word_probabilities(word_counts,type_total_counts,self.types,self.k)
def classify(self,content):#获得属于各类别的概率
return word_probability(self.word_probs,content,self.types)
def gettype(self,content):#获得预测类别
classify_probs=self.classify(content)
max_prob=max(classify_probs)
max_prob_index=classify_probs.index(max_prob)
return self.types[max_prob_index]
def score(self,test_set):#传入测试集
test_index=[test_item[1] for test_item in test_set]
pred_index=[]
for test_item in test_set:
content_prob=word_probability(self.word_probs,test_item[0],self.types)
pred_index.append(content_prob.index(max(content_prob)))
return np.mean(np.array(test_index)==np.array(pred_index))
使用方法
>>> types=["新闻","体育","汽车","房产","旅游","教育","时尚","科技","财经","娱乐"]
>>> dataset=loadExcel("dataset.xlsx","Sheet1")
>>> random.shuffle(dataset)
>>> training_set=dataset[:70]
>>> test_set=dataset[70:]
>>> nbc=NaiveBayesClassifier(types)
>>> nbc.train(training_set)
>>> content="""北京时间9月14日消息,2022赛季中超联赛第18轮联赛继续进行,北京国安在日照主场迎来了副班长河北队的挑战。上半场张稀哲点射,陈运华扳平,王子铭建功,下半场张玉宁锁定胜局,最终北京国安3-1击败河北队,新帅斯坦利上任后取得首胜。国安在换帅 之后,上轮联赛2-2战平了浙江队,尽管在技战术层面并没有过多的变动,但是球员们的精气神却与以往不同,斗志更强了,本轮对阵垫 底的河北队,两队实力相差明显,国安新帅斯坦利大概率将会在本场比赛展现出更多的自己带队的风格,如果取胜,那么御林军也将会在积分榜上继续向前追赶。相关阅读-媒体人:国足选帅别急着上马 不想明白谁上也白废比赛开始后第4分钟,高天意在中路寻求突破,随 后左脚远射被鲍亚雄轻松抱住;第6分钟,张稀哲开出左侧任意球,柏杨禁区内争顶头球攻门高出横梁;第9分钟,高华泽禁区右侧过掉姜祥佑之后小角度抽射被柏杨挡出;第15分钟,于大宝中场输送直塞,张玉宁甩开防守不停球直接爆射被鲍亚雄扑出底线;第16分钟,张稀哲开出角球被解围,随后他再次传中,于大宝后点头球回做,王子铭将球拨进球门,不过经过VAR回看,助攻的于大宝在张稀哲传球时越 位,进球无效;"""
>>> nbc.classify(content)
[-1100.7245522663443, -1007.8436308839352, -1230.5955078582558, -1131.7388604926687, -1168.1510738024772, -1233.9717449797113, -1201.7283979422293, -1157.891144823666, -1119.596931376088, -1190.116854852187]
>>> nbc.gettype(content)
"体育"
其他
btw,这本《数据科学入门》还是很适合新入门机器学习的朋友的,不是上来就告诉你怎么掉包,而是将实现原理告诉你,并将实现代码附上。之前看过的《Python机器学习基础教程》,其实也不错,k近邻这一章用莺尾花的例子将这个方法讲得很透彻,不过越到后面,对于细节描述会更少,对于像我们这种统计学基础较少的小白来说还是不太友好的,更多告诉你如何调参数,不太利于理解。不过你原本就有不错的统计学、概率论基础,看这本书应该也是个不错的选择。另外本人在机器学习方面仍处于摸索阶段,如有不正确之处还望海涵,若能指出问题更是感激不尽。
-
最新文章
- 爱尔法鲁酒吧问题python实现,复杂经济学博弈论自组织自适应系统
- python字体子集化
- 一些用平板画的画和用flipaclip画的动画
- phpcms通用缓存装饰器,给函数的输出增加缓存
- python根据行业根词及百度百科提取行业属性
- python使用朴素贝叶斯实现简单中文文本分类
- 基于时间戳与对称加密实现简单的token验证
- 递归打印出树形结构数据(多层级数据)(小思考)
-
最新随笔
- 增加一些流动的云
- 文章页也调整了下(图一旧,图二新)
- 给首页调了下样式,图一旧版、图二新版。vibe coding之后,改起老项目反倒成了一种娱乐。
- 昨天睡觉的时候反复梦到“人本主义”这个词,可是最近好像都没有相关的知识接触过,半梦半醒的时候还去搜了下具体含义,找了些视频看了下
- 在AI时代尽可能在行业、学科的宽度上扩展,尽量尝试一些跨学科的事情、阅读一些跨学科的书籍和资料,应该会有很大收益。
- 跟qoder和deepseek一起把之前想做的一些人生管理系统整合到博客上了,感觉还不错,顺便让它们帮我弄了一个数据大屏,放在平板上实时播放也不错。本来想单独做成独立的系统,想想感觉徒增维护成本,那就干脆合并到博客了。也能增加自己打开博客的频率,增加输出内容的概率。
- 改了下首页的顶部banner,加了个背景图,新旧对比
- 让qodercli改了改博客,这速度效率真的史无前例地高,连commit和push都交给它了。效果和claudeCode有的一比,用了一段时间,真的还可以。