在互联网中,传输数据有各种各样的协议,比如我们经常会接触到的http协议,一般用于web传输,还有用于邮件传输的smtp、pop3协议,用于传输文件的FTP协议等等,这些协议在网络分层中属于应用层协议,是基于位于传输层的TCP协议封装的,所以今天我们要来尝试使用python的内置库与模块基于TCP用http协议规范实现一个类似apache的静态资源服务器。
一、所需库与模块
socket
threading
datetime
os
pathlib
二、http协议报文
在开始在写程序之前,我们先来了解一下http协议的报文,http协议中,有两种类型的报文,分别为请求报文与响应报文;客户端在浏览器向服务器发送一个请求报文,服务器返回一个响应报文,这就是一次http通信(在这里我们不用考虑TCP的握手与分手)
我们来看看请求报文与响应报文的结构吧
请求报文结构
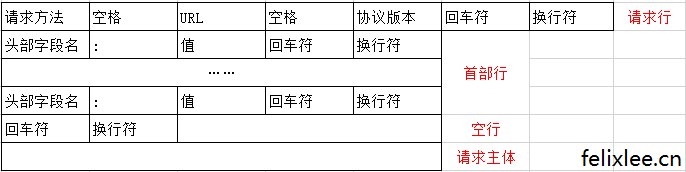
请求报文示例

响应报文结构
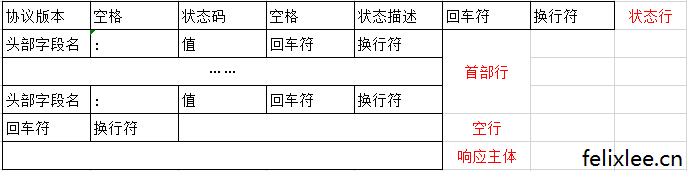
响应报文示例
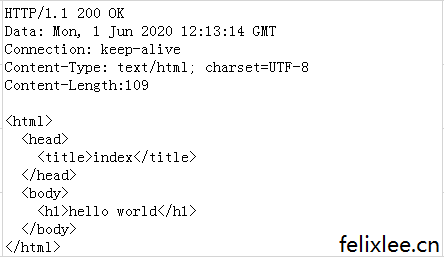
三、思路
在这个程序中,使用socket中的TCP协议作为基础,监听地址,接收来自浏览器的请求;我们把请求和响应都分别看成对象,一个请求为一个请求对象,一个响应为一个响应对象;在请求类中接受请求报文用于构造请求对象,在响应类中可预先生成一个响应对象,然后调用方法将请求对象作为参数输入来构造响应对象,或者直接按需修改对象属性
响应的内容有三种大类,一种是静态文件,一种是目录,还有自定义的404与500页面
我们实现的服务器一共有四种状态码,包括200、301、302、404,500分别表示响应成功、永久重定向、临时重定向、资源不存在、服务器内部错误。
在服务器程序的同级目录下创建一个名为www的文件夹用于存放静态资源,请求的url对应www文件夹下的路径。
四、开始动手
首先我们先实现一个请求类,接收请求报文用于构造请求对象,对象的属性有请求方法、请求路径、协议版本、首部行字段以及请求主体,首部行字段是字典形式。
请求类
class Request(object):
def __init__(self,req):
self.__chips=req.split('\r\n')
self.__RLChips=self.__chips[0].split(' ')
self.method=self.__RLChips[0]
self.URL=self.__RLChips[1]
self.version=self.__RLChips[2]
self.headers=self.__getHeaders()
self.requestBody=self.__chips[-1]
def __getHeaders(self):
header=self.__chips[1:-2]
headerDict={}
for i in header:
key,value=i.split(': ',1)
headerDict[key]=value
return headerDict
接着我们写一个简单的html模板用于自定义404与500页面和目录页面
htmlTemplate='''<!DOCTYPE html>
<html>
<head>
<title>{title}</title>
</head>
<body>{content}</body>
</html>
'''
添加用于储存文件后缀与content type关系的字典,这里我只写了几个常见的类型,需要更多类型的同学可以查看contentType对照表然后添加到EXTS字典中即可;
EXTS={'jpg' :'image/jpeg',
'jpeg':'image/jpeg',
'png' :'image/png',
'ico' :'image/icon',
'htm' :'text/html',
'html':'text/html',
'js' :'application:x-javascript',
'css' :'text/css',
'txt' :'text/plain'}
然后,我们来实现一个响应类,用于构造响应对象,ext表示请求的文件的拓展名,这里不直接在初始化方法中处理请求而是调用dealRequest方法来处理请求构造响应对象,因为这样方便在生成响应对象后自定义属性。
响应类
import datetime
import os
from pathlib import Path
class Response(object):
def __init__(self):
self.version='HTTP/1.1'
self.date=datetime.datetime.now().strftime('%a, %d %b %Y %H:%M:%S GMT')
self.contentType='text/html'
self.ext=''
def dealRequest(self,request):
self.version=request.version
self.URL=request.URL
self.path=os.path.join('www',request.URL[1:])
self.ext=self.path.split('.')[-1] if '.' in self.path else ''
self.statusCode,self.statusDesc=self.__ifExist()
self.content=self.__getContent()
self.contentType=self.__getType()
我们用os模块来判断请求的url在本地是否存在相对应的路径,并且返回响应对象的状态码与状态描述
def __ifExist(self):#是否存在
exist=os.path.exists(self.path)
if exist:
return ['200','OK']
else:
return ['404','Not Found']
接着实现一个生成响应主体内容的方法,通过判断状态码来生成不同的响应内容;
当状态码为200时,通过pathlib中的Path函数判断请求的本地路径为文件路径亦或是目录路径;
若路径为文件路径则用二进制形式读取文件内容,尝试解码为文本返回,若捕获错误则直接返回二进制数据;
若路径为目录路径则通过os模块的listdir函数与pathlib的Path函数循环目录下的所有文件与目录,并配合之前写的html模板生成返回的目录页面,在这个程序中URL的/表示层级关系,映射到本地路径的层级关系,在URL中结尾带/比不带/更适合表示一个目录,所以在这个方法中,将结尾不带/的目录URL永久重定向到带/的URL上;
当状态码为404时,返回一个404页面
def __getContent(self):#生成响应内容
if self.statusCode=='200':
if Path(self.path).is_file():#路径为文件路径时
with open(self.path,'rb') as f:
page=f.read()
try:
return page.decode('utf-8')
except:
return page
else:#路径为目录路径时
content=''
if self.URL[-1]!='/':#不带/的目录URL重定向到带/的目录URL
self.redirect(self.URL+'/',tem=False)
return ''
for i in os.listdir(self.path):
if Path(os.path.join(self.path,i)).is_dir():
i=i+'/'
content=content+'<li><a href="%s">%s</a></li>' %(self.URL+i,i)
if self.URL!='/':
content='<li><a href="../">../</a></li>'+content #非首页时添加返回上一级的链接
title='Index of '+self.URL
content='<h1> '+title+'</h1><hr/>'+'<ul>'+content+'</ul>'
return htmlTemplate.format(title=title,content=content)
elif self.statusCode=='404':
return htmlTemplate.format(title='404 Not Found',content='<h1>404 Not Found</h1>')
else:
return ''
下面我们还要实现一个返回content type的方法,通过文件的拓展名来返回对应的content type,只有在当状态码为200且请求文件的拓展名在EXTS中,才会返回对应的content type,否则返回text/plain,自定义页面与目录页面返回text/html;这里多加一个判断是否为文件是因为有些文件是没有后缀的,这样做以区分文件夹。
def __getType(self):#文件类型
if self.statusCode=='200' and Path(self.path).is_file():
return EXTS[self.ext] if self.ext in EXTS else 'text/plain'
else:
return 'text/html'
接下来我们再把前面要用到的重定向方法实现一下,调用重定向方法后添加了一个新的location属性,为重定向的目标地址
def redirect(self,url,tem=True):#重定向 默认tem=True为302临时重定向,tem=False为301永久重定向
if tem:
self.statusCode='302'
self.statusDesc='Moved Temporarily'
else:
self.statusCode='301'
self.statusDesc='Moved Permanently'
self.location=url
最后需要为对象写一个生成响应头部的方法,按照http响应报文格式来生成,并用@property装饰成一个属性
@property
def header(self):#生成响应头部
statusLine=self.version+' '+self.statusCode+' '+self.statusDesc
baseHeader=statusLine+\
'\r\nDate: '+self.date+\
'\r\nContent-Type: '+self.contentType+\
'\r\nContent-Length: '+str(len(self.content))
if self.statusCode=='302' or self.statusCode=='301':
baseHeader=baseHeader+'\r\nLocation: '+self.location
return baseHeader+"\r\n\r\n"
到这里我们就实现了简单的请求与响应类,接下来我们就根据上面实现的两个类来写一个简单的静态文件服务器,在这里我们try...except...来捕获错误,如果出现程序内部错误就构造一个500的页面返回给客户端。
import socket
import threading
def http(sock,addr):
buffer=b''
while True:
data=sock.recv(1024)
buffer=buffer+data
if len(data)<1024:
break
data=buffer.decode('utf-8')
if len(data)==0:#当接收的数据为空时,则退出连接
sock.close()
return ''
response=Response()
try:
request=Request(data)
response.dealRequest(request)
except:
response.statusCode='500'
response.statusDesc='Internal Server Error'
response.content=htmlTemplate.format(title='500 Internal Server Error',content='<h1>500 Internal Server Error</h1>')
sock.send(response.header.encode('utf-8'))#发送头部
if isinstance(response.content,bytes):
sock.send(response.content)#send bytes
else:
sock.send(response.content.encode('utf-8'))#send document
print(addr[0]+' === '+request.method+" === "+request.URL+" === "+response.statusCode)
sock.close()
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.bind(('0.0.0.0',5000))
s.listen(5)
print('httpserver running...')
while True:
try:
sock,addr=s.accept()
t=threading.Thread(target=http,args=(sock,addr))
t.start()
五、测试一下
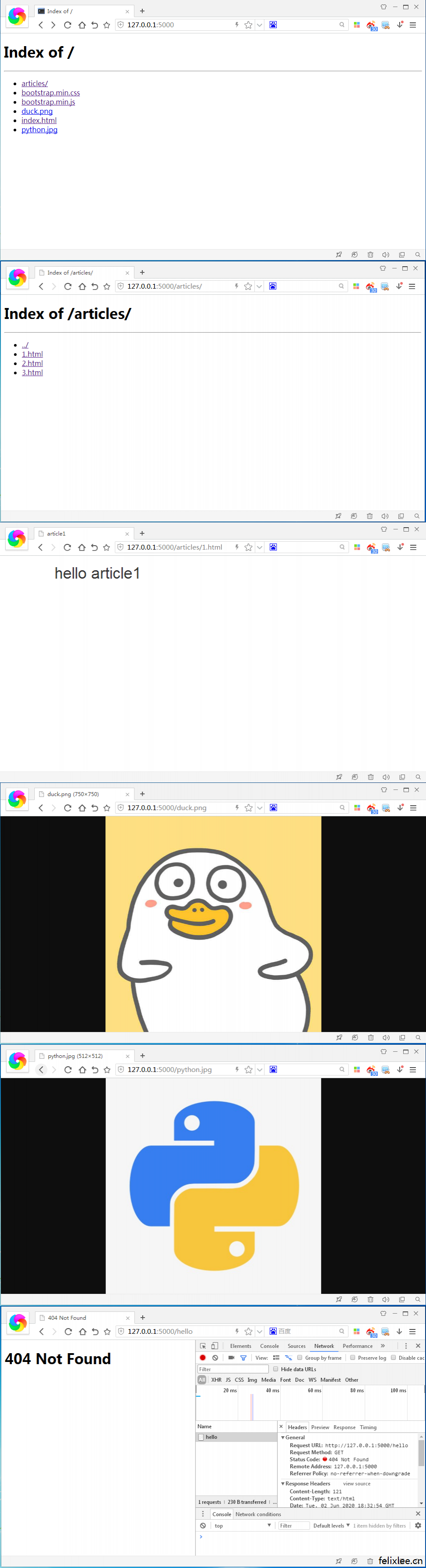
我们将上述代码保存到一个server.py文件中,在同级目录下添加一个www文件夹,在www文件夹中添加一些文件与文件夹,下面是文件夹结构一览
server.py
www/
|--articles/
|--1.html
|--2.html
|--3.html
|--bootstrap.min.css
|--bootstrap.min.js
|--duck.png
|--index.html
|--python.jpg
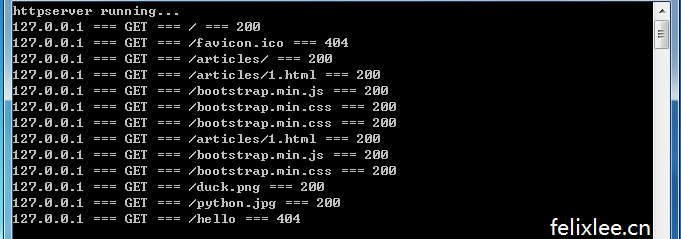
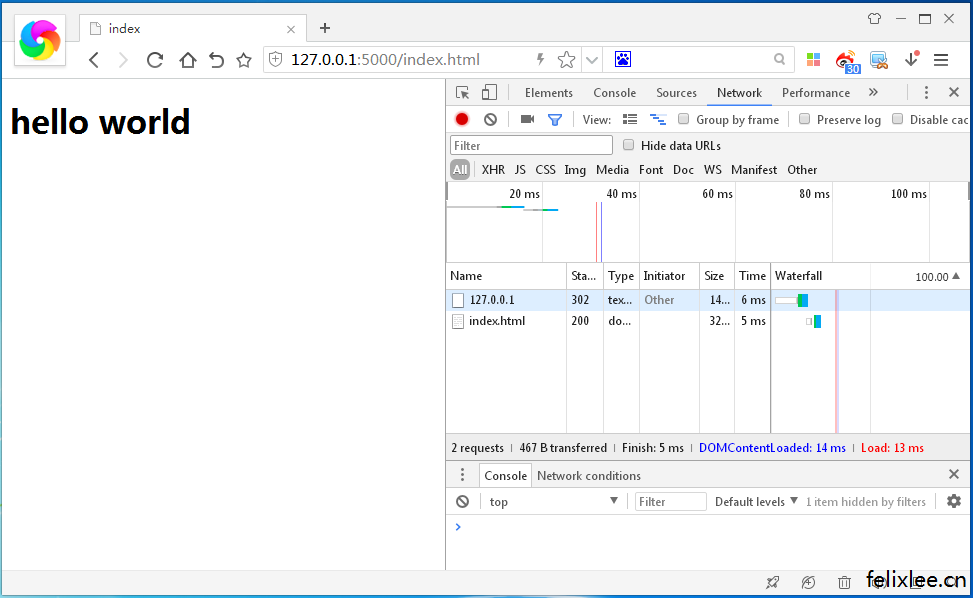
运行服务器程序,打开浏览器访问127.0.0.1:5000
在命令行显示为下面这样的格式
如果需要重定向可以这样设置
...
request=Request(data)
response=Response()
if request.URL=='/':
response.redirect('/index.html')
...
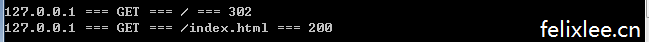
接下来我们来测试一下访问未预先添加的类型会怎么样,在www文件夹中添加mouse.swf、hello.py、test,分别为二进制文件、文本文件与无后缀的文件
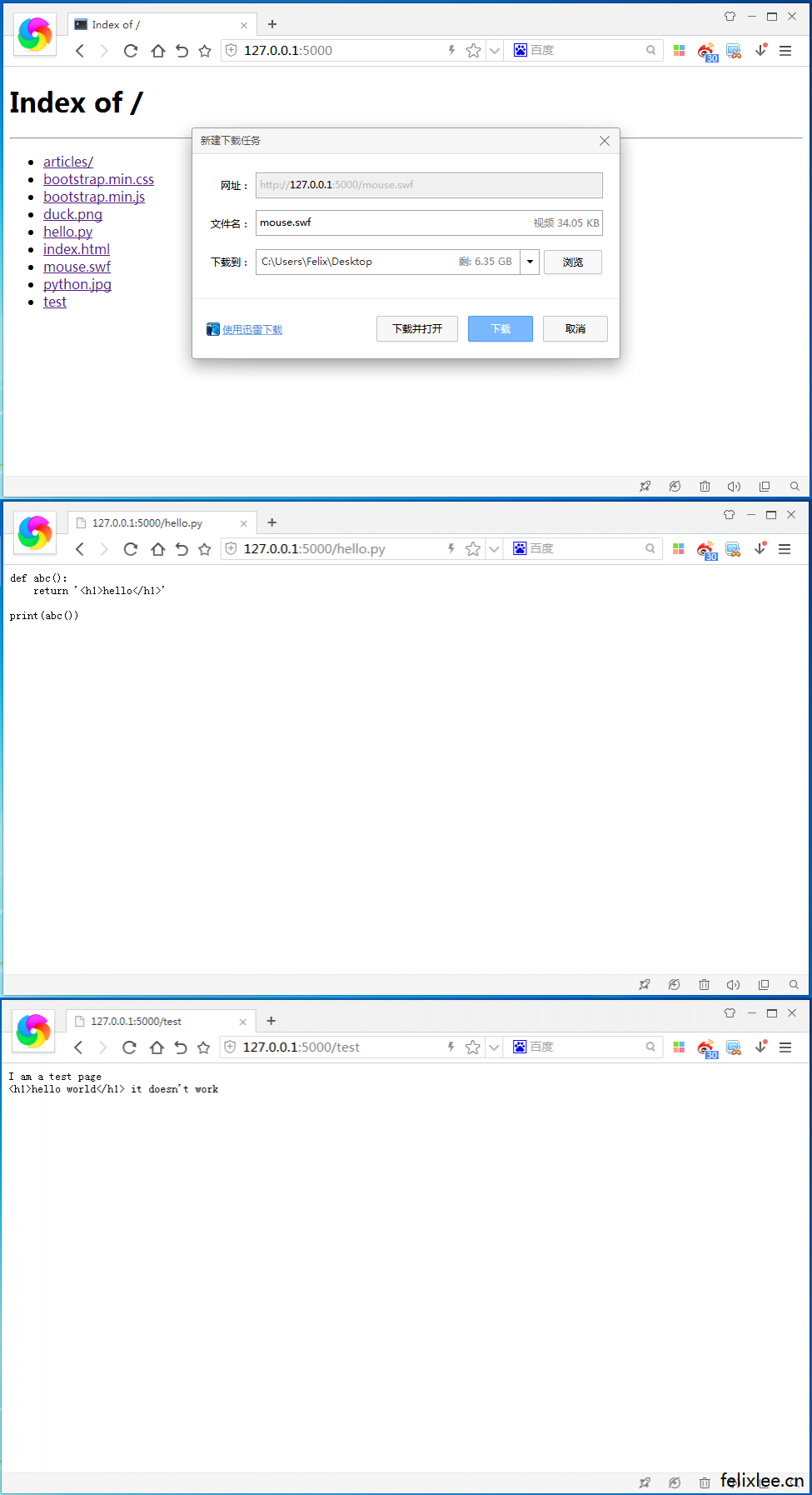
当访问未知后缀文件时,二进制文件返回下载,其他文件就直接返回文本形式。
最后我们测试一下500错误,在响应类里随便引用一个未定义过的变量,重启服务器后打开浏览器查看
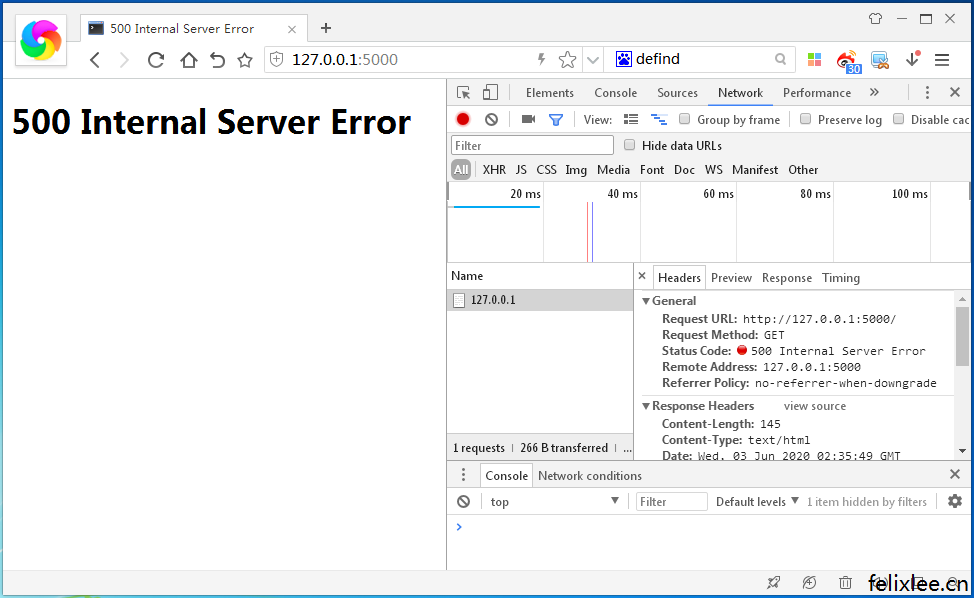
六、其他
以上就是一个简单的http静态资源服务器啦,实现起来还是比较简单的,也是挺有趣的,能了解一下http协议的一些原理。当然,这个程序还有许多可以完善,比如可以把content type类型完善一下,也可以将程序配置信息独立到单独的一个文件上等等。下面是这个程序的仓库地址,我有空也会完善优化更新一下程序并提交到仓库上
http://codemole.cn/felix/httpserver
希望上面的教程能对你有所帮助,如果您在文章发现了任何错误或者有一些建议、问题的话,欢迎在下面评论,我看到了会及时回复的。
-
最新文章
- 爱尔法鲁酒吧问题python实现,复杂经济学博弈论自组织自适应系统
- python字体子集化
- 一些用平板画的画和用flipaclip画的动画
- phpcms通用缓存装饰器,给函数的输出增加缓存
- python根据行业根词及百度百科提取行业属性
- python使用朴素贝叶斯实现简单中文文本分类
- 基于时间戳与对称加密实现简单的token验证
- 递归打印出树形结构数据(多层级数据)(小思考)
-
最新随笔
- 增加一些流动的云
- 文章页也调整了下(图一旧,图二新)
- 给首页调了下样式,图一旧版、图二新版。vibe coding之后,改起老项目反倒成了一种娱乐。
- 昨天睡觉的时候反复梦到“人本主义”这个词,可是最近好像都没有相关的知识接触过,半梦半醒的时候还去搜了下具体含义,找了些视频看了下
- 在AI时代尽可能在行业、学科的宽度上扩展,尽量尝试一些跨学科的事情、阅读一些跨学科的书籍和资料,应该会有很大收益。
- 跟qoder和deepseek一起把之前想做的一些人生管理系统整合到博客上了,感觉还不错,顺便让它们帮我弄了一个数据大屏,放在平板上实时播放也不错。本来想单独做成独立的系统,想想感觉徒增维护成本,那就干脆合并到博客了。也能增加自己打开博客的频率,增加输出内容的概率。
- 改了下首页的顶部banner,加了个背景图,新旧对比
- 让qodercli改了改博客,这速度效率真的史无前例地高,连commit和push都交给它了。效果和claudeCode有的一比,用了一段时间,真的还可以。