生命不止,折腾不停,最近开始接触了wordpress,发现wordpress真的做得很不错,有很多地方值得学习,很多地方也设置得非常巧妙。在刚安装完了wp后就会有一篇“世界你好”的文章,有点空荡荡,所以我在想可不可用python为wordpress采集一些内容再自动发布上去呢,那么话不多说,让我们开干吧
一、所需库与模块
requests 是一个模拟http请求的库,我们用它来爬取网页。
lxml 是一个解析HTML与XML的库,我们用它来解析网页内容
pymysql 是一个操作MySql的库,我们用它来上传内容到wordpress的数据库
time 是python内置的一个处理时间的模块,我们用它来设置爬取网页的间隔时间
random 是一个python内置的生成随机数的模块,我们用它来生成随机的间隔时间
xpinyin 是一个将汉字转换成拼音的库
二、使用pymysql提交内容到wordpress数据库
一般我们在使用wordpress时都是在后台上面写完然后点击发布,这个过程是这样子的:
浏览器=>form提交=>php=>数据库
而这里我们要跳过前面三个步骤,直接对接数据库:
命令行=>数据库
在通过查看wordpress数据库的wp_posts表的字段后,我写了一段sql语句,并预留了三个位置,为content,title,name,分别代表文章内容,标题,在url显示的名字。
sqlbase="INSERT INTO wp_posts(post_author,post_date,post_date_gmt,post_content,post_title,post_status,comment_status,ping_status,post_name,post_modified,post_modified_gmt,post_parent,menu_order,post_type) VALUE(1,now(),DATE_ADD(now(),INTERVAL '-8' HOUR),'%s','%s','publish','open','open','%s',now(),DATE_ADD(now(),INTERVAL '-8' HOUR),0,0,'post')"
我们要生成一段插入文章的sql语句时就可以这样写
sql=sqlbase % (content,title,name)
接下来要将sql语句提交到wordpress的数据库,这里就需要用到一个python的第三方库pymysql
import pymysql
sqlbase="INSERT INTO wp_posts(post_author,post_date,post_date_gmt,post_content,post_title,post_status,comment_status,ping_status,post_name,post_modified,post_modified_gmt,post_parent,menu_order,post_type) VALUE(1,now(),DATE_ADD(now(),INTERVAL '-8' HOUR),'%s','%s','publish','open','open','%s',now(),DATE_ADD(now(),INTERVAL '-8' HOUR),0,0,'post')"
def upload(title,content,name):
sql=sqlbase % (content,title,name)
db=pymysql.connect('数据库ip','数据库用户名','数据库密码','数据库名')
cursor=db.cursor()
try:
cursor.execute(sql)
db.commit()
except Exception as e:
db.rollback()
print(e)
db.close()
将提交到wordpress数据库这个操作整合到一个函数中,这样我们在后面使用就会方便一些,将函数中的连接信息修改成wordpress数据库的信息,然后我们来测试一下
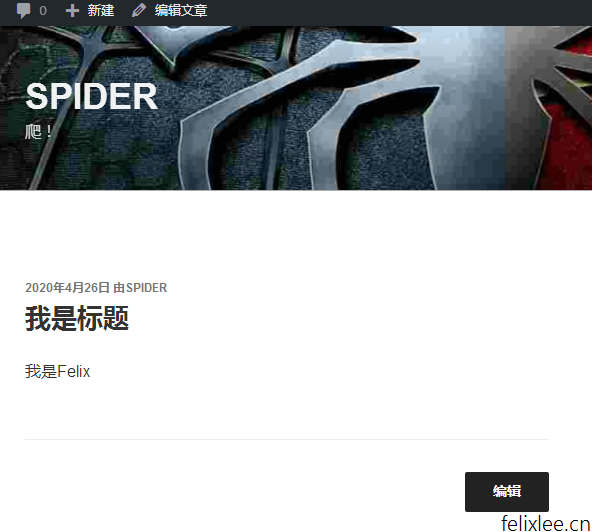
>>>upload('我是标题','<p>我是Felix</p>','wo-shi-biao-ti')
因为观察wp_posts表时有些字段内容为空,所以在sql语句中我就没有写,在第一次运行upload()时会有一些提示信息说某些字段为空,忽略即可,然后我们打开wordpress查看
三、爬取内容并上传
在这里,为了方便演示我就选择一个静态的小说网站,在爬取小说网站时,我们主要爬取两种类型的网页,分别为目录页与章节页(文章页)
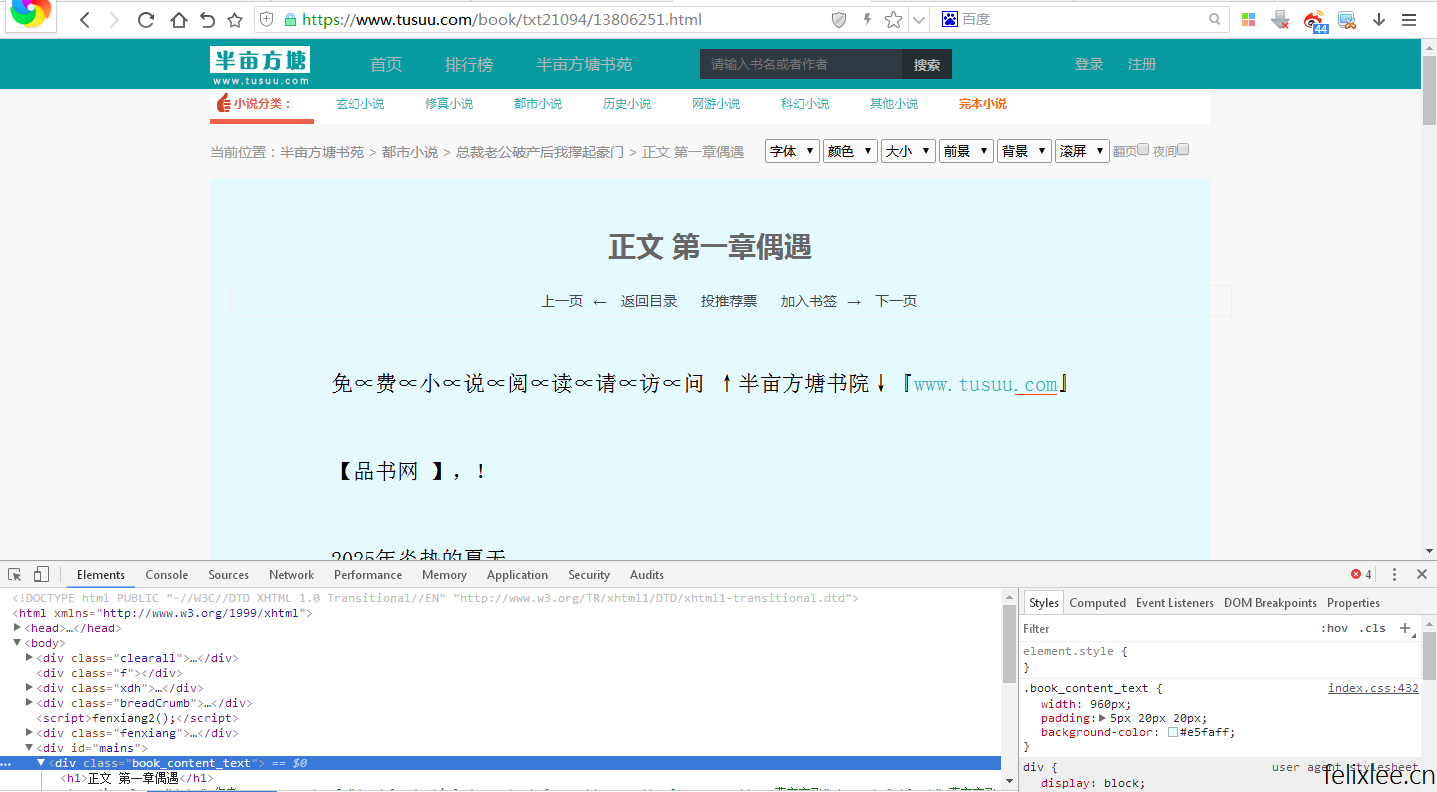
首先观察章节页,找到章节标题与内容的对应class或者id,通过lxml找到对应的内容,然后根据自己的需求删除或裁剪一些不需要的内容,还有需要注意一下网站的编码问题,这个小说网站直接打印出爬取的内容是乱码所以需要进行一下转码,这里我写了一个的抓取章节页内容的函数
from lxml import etree
import requests
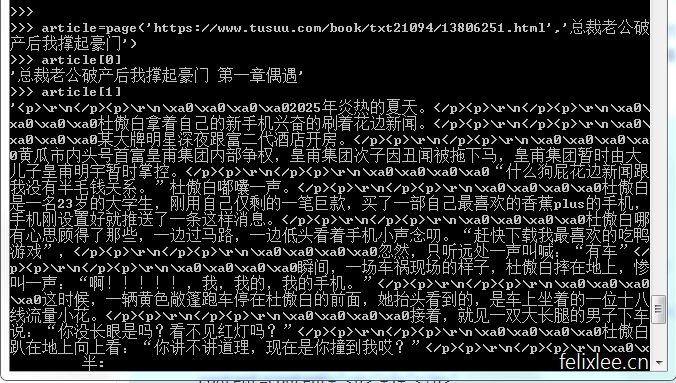
def page(url,booktitle=''):
response=requests.get(url)
response.encoding='gbk'
html=etree.HTML(response.text)
chapter_title=html.xpath('//h1/text()')[0].split('正文')[1]
title=booktitle+chapter_title
content_list=html.xpath('//div[@id="book_text"]/text()')[4:][:-1]
content=''
for i in content_list:
content=content+'<p>'+i+'</p>'
return [title,content]
测试一下
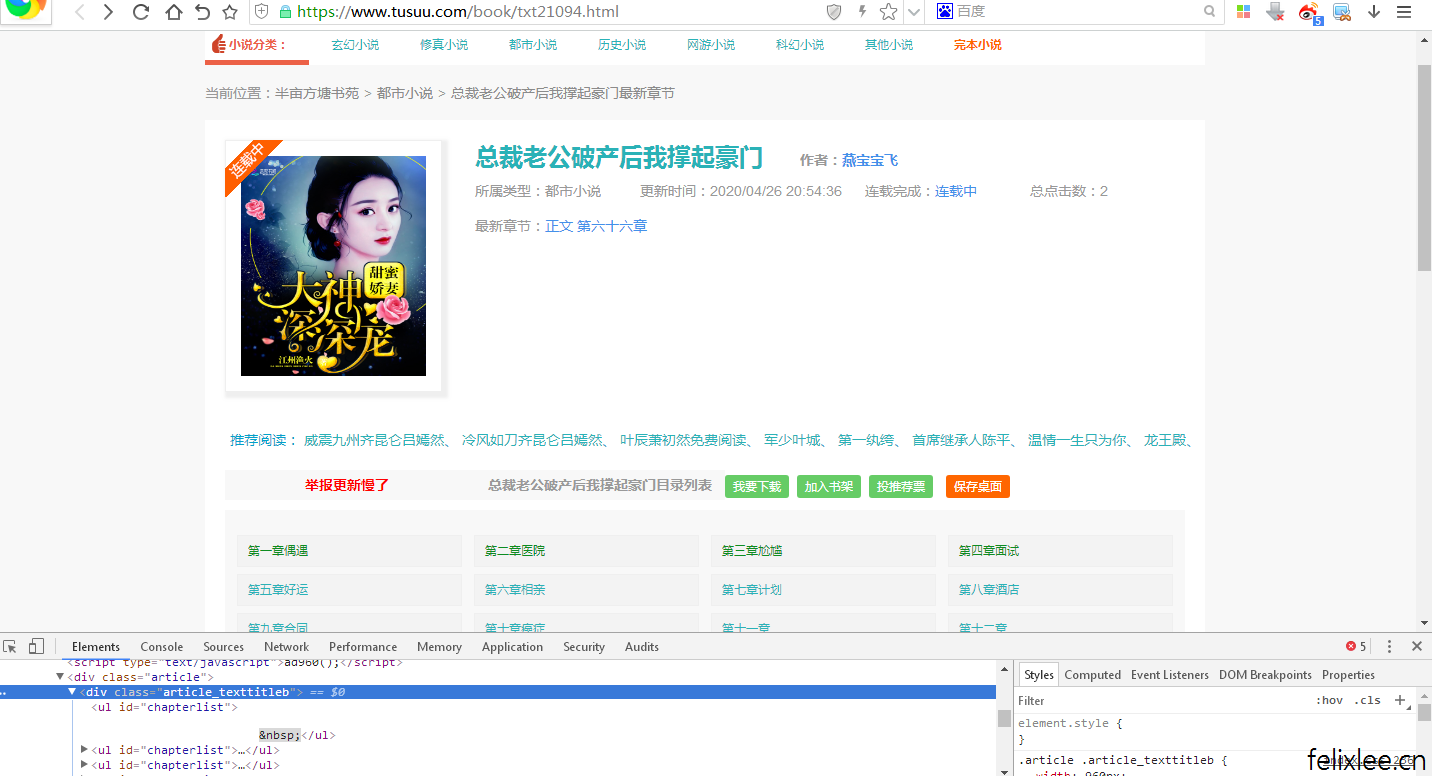
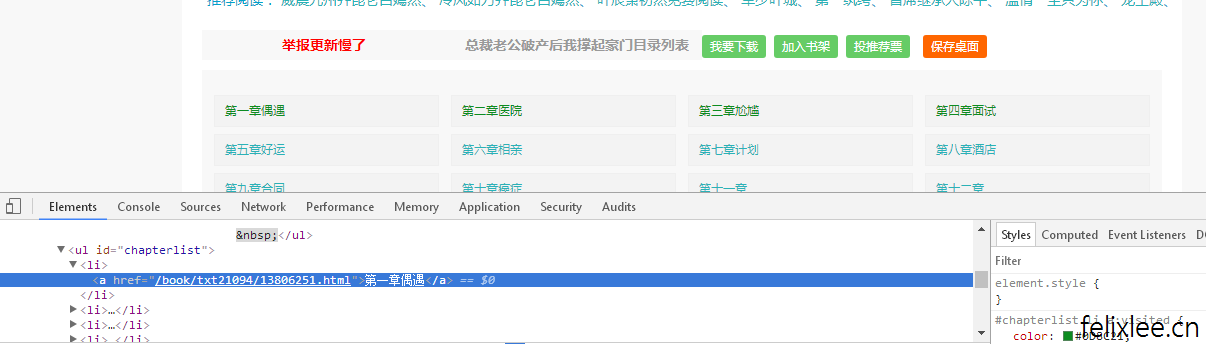
接下来我们来分析一下目录页,抓取书名与所有章节的链接,可以看到目录页的章节链接是相对地址,所以我们要加上网站的域名将其变为绝对地址,然后我们用time模块与random模块来生成一段时间范围内的随机爬取间隔时间,并且通过第三方库xpinyin来生成wordpress的url所需要的name,下面写了一个menu函数来完成以上操作,输入的参数为目录url与最小爬取间隔时间
import time
import random
from xpinyin import Pinyin
p=Pinyin()
def menu(url,min_time):
response=requests.get(url)
response.encoding='gbk'
html=etree.HTML(response.text)
booktitle=html.xpath('//h1/text()')[0] #书名
page_links=html.xpath('//div[@class="article_texttitleb"]//a/@href') #所有章节链接
i=0
for link in page_links:
i=i+1
try:
article=page('https://www.tusuu.com'+link,booktitle)
name=p.get_pinyin(article[0])
upload(article[0],article[1],name)
print('page%s finished!' % i)
time.sleep(random.randint(min_time,min_time+60))
except Exception as e:
print('page%s failed!' % i)
print(e)
print('All done!')
让我们来测试一下,为了不对别人的网站造成困扰还有不对别人的服务器造成压力,所以这里的最小间隔时间我设置为5分钟即300秒,程序就会在5到6分钟之间进行一次爬取。
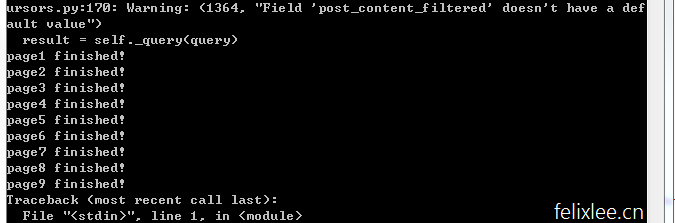
>>>menu('https://www.tusuu.com/book/txt21094.html',300)
然后我们隔一段时间再来看一下,因为仅用于测试,所以在第九章时便Ctrl+C退出
四、为文章添加分类(可选)
wordpress并没有强制要求文章要设置分类,如果你需要为文章添加分类,可以看一下下面的方法。
wordpress数据库跟分类有关的有三个表wp_terms,wp_term_relationships,wp_term_taxonomy
wp_term是记录所有分类

wp_term_relationships是记录文章与分类关系

wp_term_taxonomy是记录分类的父分类,分类描述与分类下的文章总数

我们首先在wp_term里找到分类的id,然后在插入文章后与commit之前通过cursor.lastrowid获取最新文章的id,这时候添加分类,接着为wp_term_taxonomy表中分类的文章统计数加一,最后再commit,这里改写了一下upload函数
category_sqlbase="INSERT INTO wp_term_relationships(object_id,term_taxonomy_id,term_order) VALUE(%s,%s,0)"
count_sqlbase="UPDATE wp_term_taxonomy SET count=count+1 WHERE term_id ='%s' "
def upload(title,content,name,cate_id):
sql=sqlbase % (content,title,name)
db=pymysql.connect('数据库ip','数据库用户名','数据库密码','数据库名')
cursor=db.cursor()
try:
cursor.execute(sql)
sql2=category_sqlbase % (cursor.lastrowid,cate_id)
sql3=count_sqlbase % cate_id
cursor.execute(sql2)
cursor.execute(sql3)
db.commit()
except Exception as e:
db.rollback()
print(e)
db.close()
upload函数多添加了一个参数cate_id为分类的id,我们来测试一下,我为wordpress添加了一个新闻分类,通过查看wp_terms表得知新闻分类id为4
>>>upload('我是新闻标题','我是新闻内容','wo-shi-xin-wen-biao-ti',4)
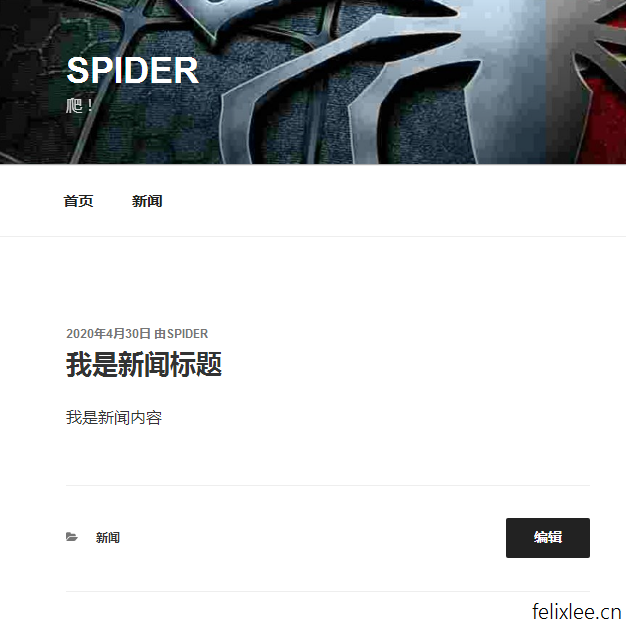
现在就可以看到文章被添加到了新闻的分类了,当然你也可以动态地添加新的分类,然后通过sql语句用名字找到对应的id。
五、其他
不同的网站一般结构都是不同的,所以上面爬取部分的代码在别的网站上一般也是用不了的,甚至因为网站更新在同一个网站也可能用不了,所以爬取部分大家可以根据自己的需要修改一下。
对于动态页面我们可以调用页面上的一些js,获取返回的结果。
如果你担心被网站禁ip,可以挂代理,或者将采集程序放到挂机宝上,也可以选择模拟百度UA,这个可以在requests上设置。
以上所使用网站仅用于学习探讨,请勿对他人网站进行频繁访问攻击,并注意版权问题,造成法律纠纷与财产损失与本站无关,请自行负责!
-
最新文章
- 爱尔法鲁酒吧问题python实现,复杂经济学博弈论自组织自适应系统
- python字体子集化
- 一些用平板画的画和用flipaclip画的动画
- phpcms通用缓存装饰器,给函数的输出增加缓存
- python根据行业根词及百度百科提取行业属性
- python使用朴素贝叶斯实现简单中文文本分类
- 基于时间戳与对称加密实现简单的token验证
- 递归打印出树形结构数据(多层级数据)(小思考)
-
最新随笔
- 增加一些流动的云
- 文章页也调整了下(图一旧,图二新)
- 给首页调了下样式,图一旧版、图二新版。vibe coding之后,改起老项目反倒成了一种娱乐。
- 昨天睡觉的时候反复梦到“人本主义”这个词,可是最近好像都没有相关的知识接触过,半梦半醒的时候还去搜了下具体含义,找了些视频看了下
- 在AI时代尽可能在行业、学科的宽度上扩展,尽量尝试一些跨学科的事情、阅读一些跨学科的书籍和资料,应该会有很大收益。
- 跟qoder和deepseek一起把之前想做的一些人生管理系统整合到博客上了,感觉还不错,顺便让它们帮我弄了一个数据大屏,放在平板上实时播放也不错。本来想单独做成独立的系统,想想感觉徒增维护成本,那就干脆合并到博客了。也能增加自己打开博客的频率,增加输出内容的概率。
- 改了下首页的顶部banner,加了个背景图,新旧对比
- 让qodercli改了改博客,这速度效率真的史无前例地高,连commit和push都交给它了。效果和claudeCode有的一比,用了一段时间,真的还可以。